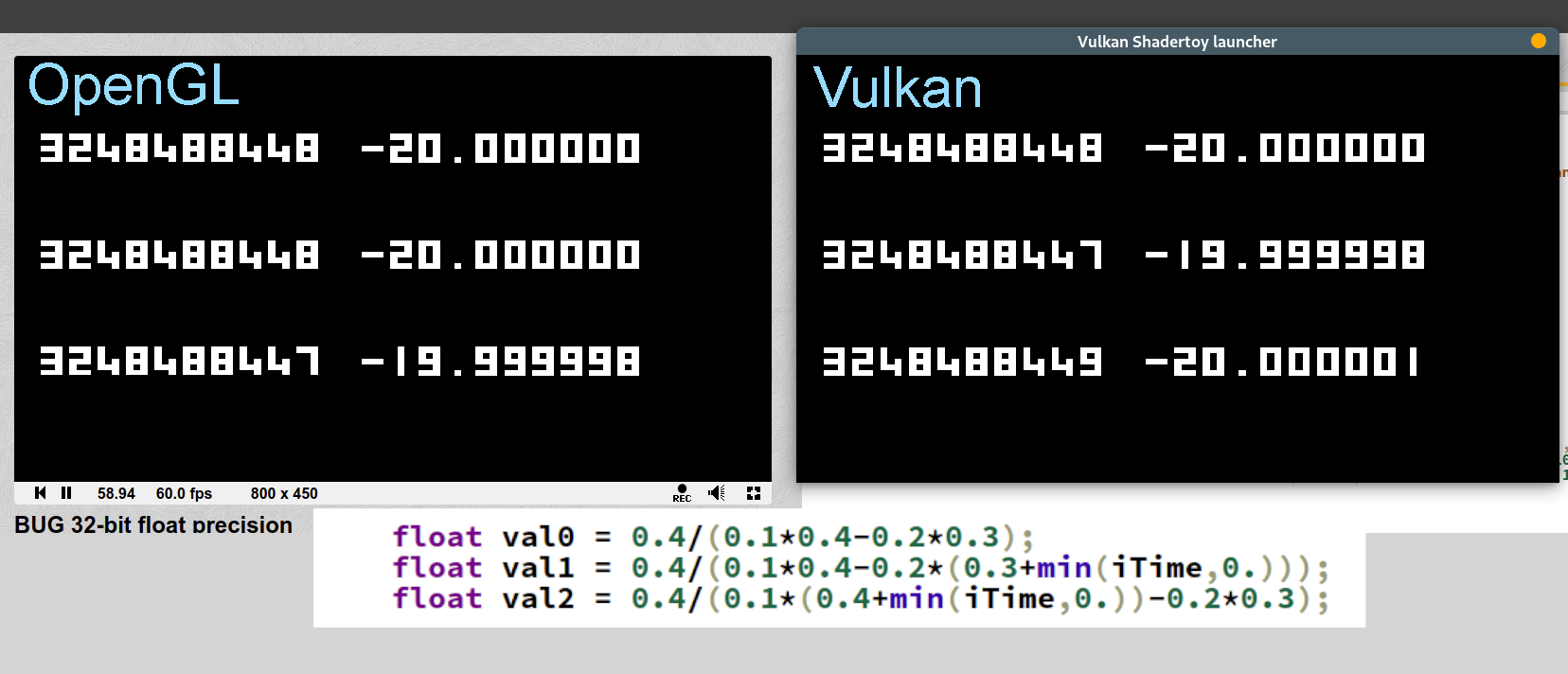
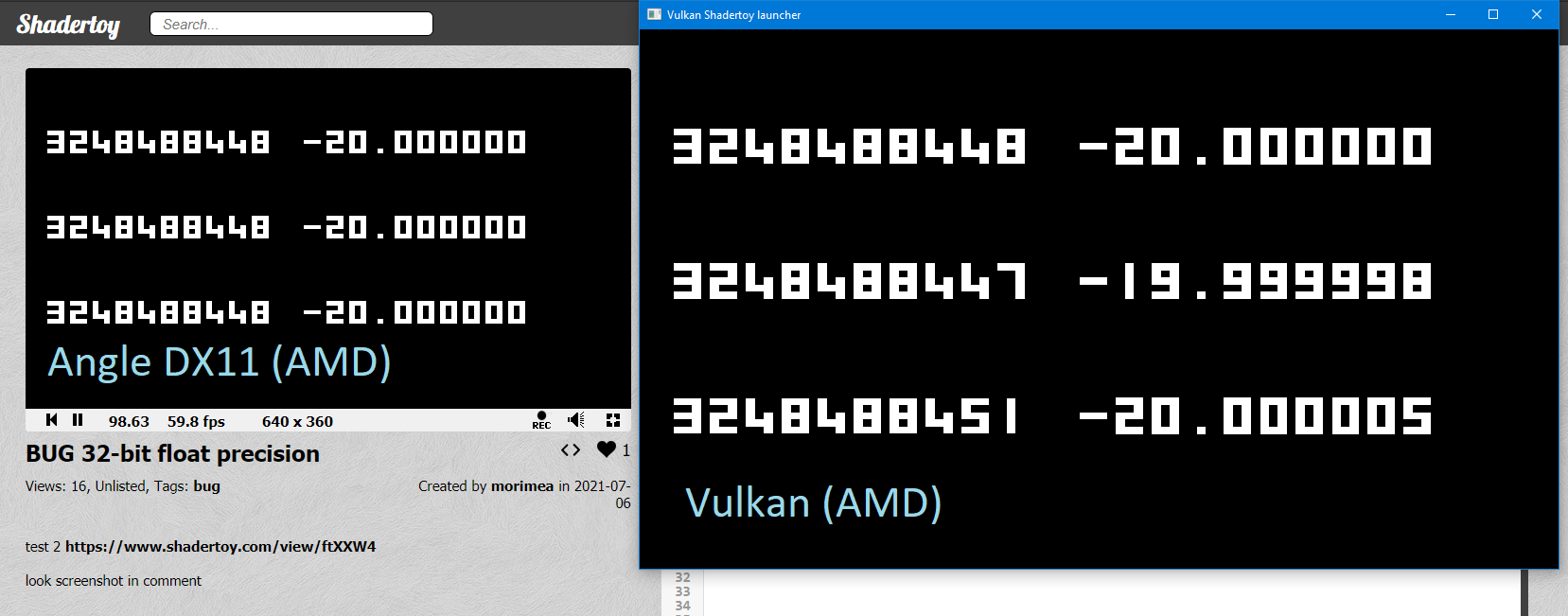
This reads to me as finding out what is meant in the “what every programmer should know about floating point” article.
GPU floating point is close to, but not quite, IEEE 754 floating point. You don't get floating point exceptions. Rounding options are different. Denormal handling is different. NAN and INF handling may be different. In games, this is rarely an issue. People trying to climb gradients for ML may care about this kind of thing. I used to do physics engines, which did some gradient climbing and sometimes had small differences between large numbers with the expected loss of significance problem. That sort of thing might be different on a GPU.
NVidia has a document on this.
In practice. most floating point problems involve:
- Subtracting two values that are very close
- Going out of range because of a near divide by zero
- Expecting mathematical identities such as sin(x)^2 + cos(x)^2 = 1 to hold precisely.
- Not having enough precision when far from the origin. If your game world is a a kilometer across, 32-bit floating point is not enough. You may have to re-origin now and then.
- Using double precision too much and losing performance.
- Doing something iteratively for too many cycles, like repeatedly multiplying rotations without re-normalizing. Like trying to go in a circle by moving along a vector and rotating the vector slightly.
Beyond that, it's time to talk to a numerical analyst.